|
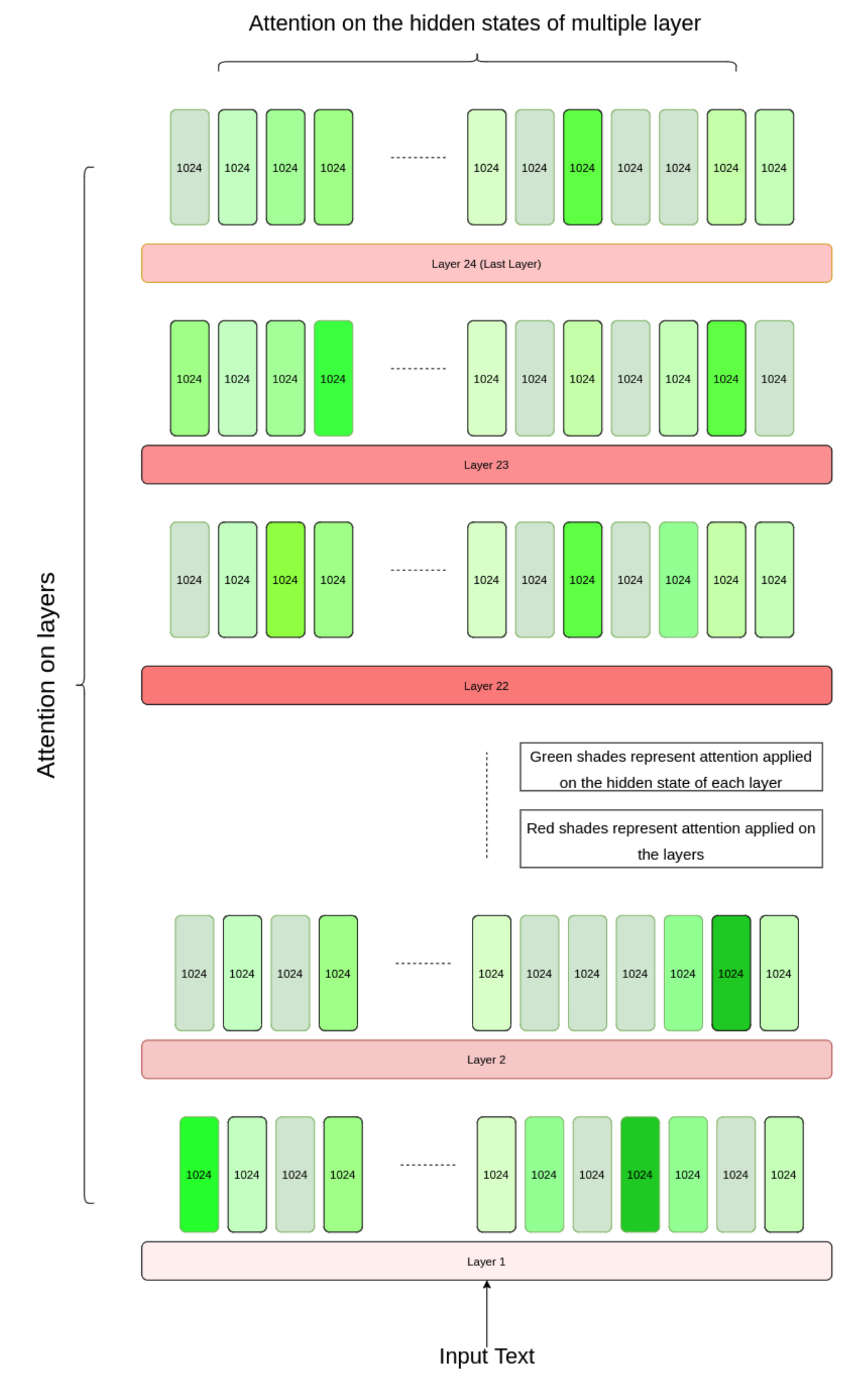
Currently I am working as an applied scientist at Amazon in the Core Search team. At Amazon I work on building scaling laws using different model sizes, and data compositions for Large Language Model based Semantic Matching Models (1B-10B scale). I am also spearheading the automated evaluation and query benchmarking to refine LLM based Semantic Matching models. I am also independently exploring the measurement of faithfulness in LLM reasoning and investigating methods to improve the Chain of Thought processes through human and self-model feedback. Previously I worked as a full-time applied scientist II at Chronograph in New York, and as a part-time researcher at the Data Science Research Lab at the University of Florida. At Chronograph, I am working on applied NLP problems in financial domain by building large foundation models. At UF, I worked on improving faithfulness in multimodal reasoning via large language models using human feedback for the DARPA funded ECOLE project. I am working under the guidance of Dr. Daisy Wang from UF, Dr. Eric Xing from CMU, and Dr. Zhiting Hu from UCSD. I graduated from University of Florida in May 2023 with a master's degree in computer science. At UF, I worked at the junction of deep learning, and natural language processing on large scale data at the Data Science Research Lab under the guidance of Dr. Daisy Wang as a research assistant. In fall of 2022, I interned at Amazon as an applied scientist in the Alexa Smart Home team under the guidance of Sven Eberhardt and Zeya Chen on researching novel transformer architecture for sequence-to-sequence problems. In summer of 2022, I interned at Apple as a machine learning researcher in the Siri Text-to-Speech team under the guidance of Kishore Prahallad and Eoin Murphy, where I worked on innovating end-to-end acoustic model on large scale speech data. Before master's, I interned at the Indian Space Research Organization (ISRO) as a machine learning researcher under the guidance of Dr. Arvind Sahay for developing neural network based solution for oceanographic problems. I received my bachelor's degree from Dharmsinh Desai University in computer engineering in 2021. At DDU, under the guidance of Dr. Brijesh Bhatt, I worked on automatic speech recognition system for low-resource language (Gujarati). I am very much open to different research domains as well as cool/hard machine learning problems. You can contact me through any of the following mediums for collaborations. Email / CV / LinkedIn / Github / Google Scholar / Kaggle / Medium Seeking full-time Research Engineer opportunities! |

|
|
|
Much of my research is at the intersection of improving faithfulness in chain of thought reasoning; training and building robust evaluations for large language models. Sparingly, I have worked on speech enhancement, automatic speech recognition, natural language understanding, prompting large language models, multimodal reasoning, dialogue managers, text-to-speech, conversational agents, and time series modeling. |
|
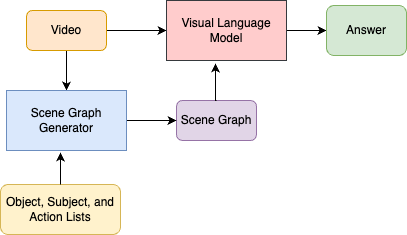
Vyom Pathak*, Haodi Ma*, Daisy Wang Under Review September 2024 [Paper] / [Slides] The recent large language models show potential in complex reasoning with textual tasks, which leads to the recent development in leveraging such models to tackle multi-modal tasks such as object recognition, action recognition, and video question answering. While these models seem to work well for image-level tasks, they tend to fail on video data which requires higher level reasoning ability such as temporal understanding. To look into the shortcomings, we evaluate SOTA works in this field on popular benchmarks like STAR and propose possible solutions to improve VLM's faithfulness with different types of information grounding. Also worked on a potential research work on Improving Faithfulness in LLM Reasoning which essential hypothetize that the chain of thought produced by LLMs are not faithful and to improve this faithfulness, we can take sub-parts of the chain of thought provide human feedback / self-model feedback, and explore this path by training on the corrected CoT using RL (OpenAI o1 model is trained on similar principles combined with a search module). A brief literature review on Reinforcement Learning from Human Feedback. |
|
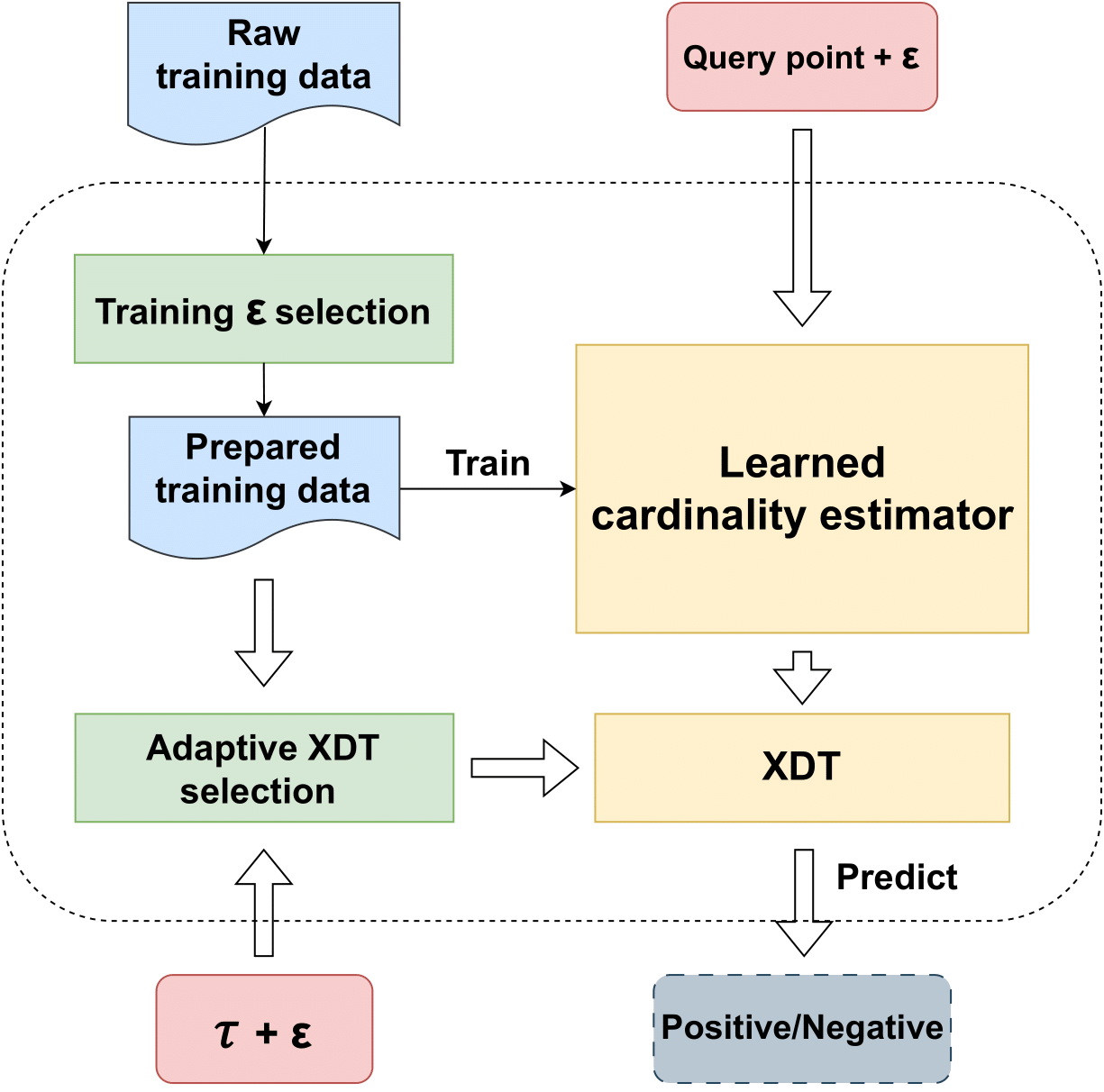
Yifan Wang*, Vyom Pathak*, Daisy Wang Arxiv Preprint February 2024 [Paper] In this paper, we propose Xling, a generic framework to build a learning-based metric space filter with any existing regression model, aiming at accurately predicting whether a query point has enough number of neighbors. The framework provides a suite of optimization strategies to further improve the prediction quality based on the learning model, which has demonstrated significantly higher prediction quality than existing MSBF. We also propose XJoin, one of the first filter-based similarity join methods, based on Xling. By predicting and skipping those queries without enough neighbors, XJoin can effectively reduce unnecessary neighbor searching and therefore it achieves a remarkable acceleration. Benefiting from the generalization capability of deep learning models, XJoin can be easily transferred onto new dataset (in similar distribution) without re-training. Furthermore, Xling is not limited to being applied in XJoin, instead, it acts as a flexible plugin that can be inserted to any loop-based similarity join methods for a speedup. |
|
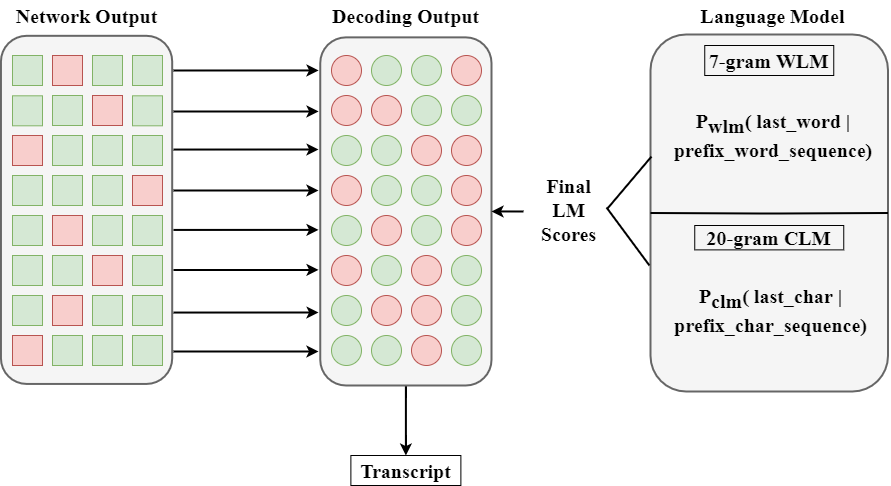
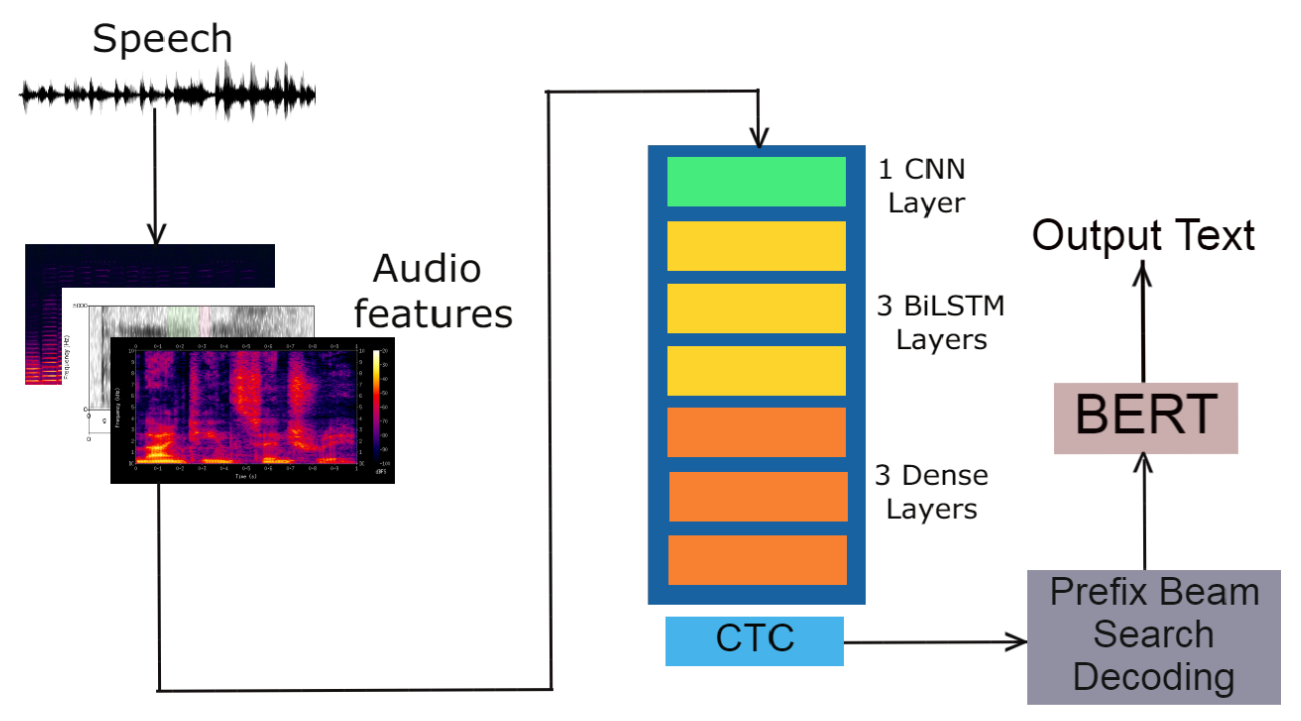
Deepang Raval*, Vyom Pathak*, Muktan Patel*, Brijesh Bhatt ACM Transactions on Asian and Low-Resource Language Information Processing (ACM TALLIP), May 2022 [Paper] / [Code] We build upon our previous work and develop higher-order character-level and word-level language models for better constraining the beam search decoding. We also provide an ablation on how to choose a good size of the language model for beam search decoding. |
|
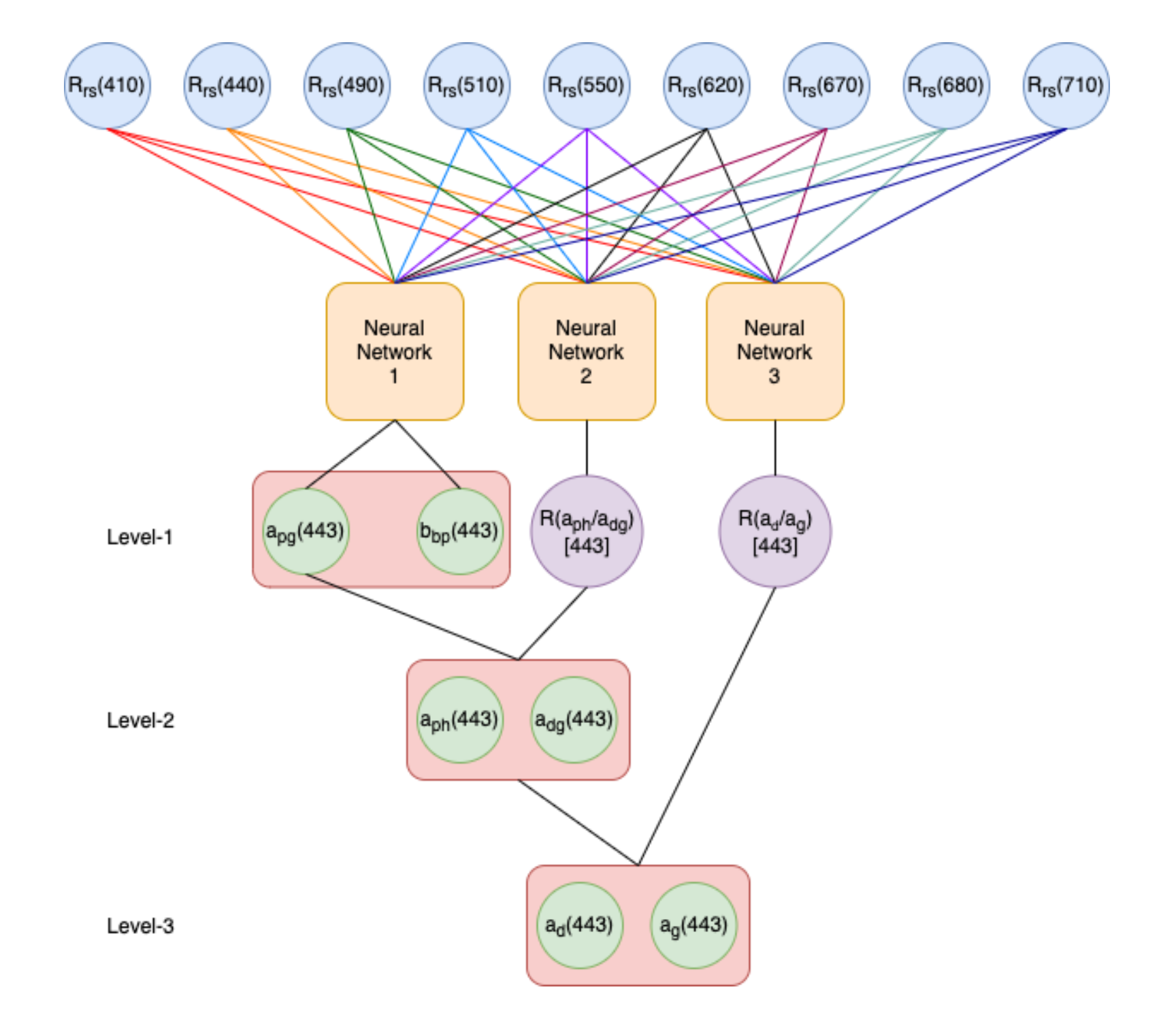
Vyom Pathak, Brijesh Bhatt, Arvind Sahay, Mini Raman International India Geoscience and Remote Sensing Symposium (InGARSS 2021) (IEEE), December 2021 [Paper] / [Code] / [Slides] We introduced a modified neural network method of deriving Inherent Optical Properties by using the remote sensing reflectance wavelengths. The proposed outperforms all other previous methods in the retrieval of each IOPs for the Insitu dataset. |
|
Deepang Raval*, Vyom Pathak*, Muktan Patel*, Brijesh Bhatt 17th International Conference on Natural Language Processing (ICON 2020) (ACL Anthology), December 2020 [Paper] / [Code] / [Oral Talk] We invented a two-tier post-processing technique to correct errors in an end-to-end ASR system for low-resource language (Gujarati). Firstly, we develop a novel multi-level (character and word level) language model for constraining the beam search decoding on the ASR output. On top of that, we developed a novel Spell Correction model based on multi-lingual BERT and a word-level language model. Finally, we provide a new and extensive analysis method to understand the errors made by the ASR system for the Gujarati Language. |
|
Along the journey of understanding machine learning, I have worked on several projects ranging from large language modeling, chat bots, protein structure degradation, kaggle competitions, and digital image processing. |
|
|
Vyom Pathak* [Slides] As an Applied Scientist at Chronograph, I led the development of an NLP pipeline to automate financial document processing, starting with a basic infrastructure of eight NVIDIA T4 GPUs. Our pipeline consisted of three stages: document classification (using Longformer, completed in 4 months), page classification (using Roberta and a novel three-stage training paradigm with a 1 million sentence dataset, completed in 5 months, leading to my promotion within 9 months), and financial metric extraction (using a fine-tuned Llama 3 8B model, completed in 4 months). We scaled our infrastructure to 8 V100s for pre-training, leveraging 200,000 pages of raw text data for that stage, and subsequently upgraded to 8 A100s for LLM training and fine-tuning. The metric extraction stage, a 4 month long project, involved heuristic-driven data collection, which was subsequently verified by human annotation. The final model, developed over 4 months, achieved a Human Eval score of 8.9/10 and a 60% exact match rate, demonstrating significant improvement over zero-shot performance. This entire 13-month project highlights the impactful application of NLP at Chronograph and positions my team at the forefront of this innovation. |
|
|
Vyom Pathak [Code] / [Slides] Language models are essential components of natural language processing that can capture general representations of language from large-scale text corpora. In recent years, various language models have been proposed, ranging from shallow word embeddings to deep contextual encoders, with different pre-training tasks, training frameworks, adaptation methods, and evaluation benchmarks. The year 2022 saw a surge in the development of large generative models, referred to as "foundation models," that can perform multiple tasks by training on a general unlabeled dataset. However, there is a need for a comprehensive survey that can link these models and contrast their advantages and disadvantages. In this paper, we present a systematic survey of foundation language models that aims to connect various models based on multiple criteria, such as representation learning, model size, task capabilities, research questions, and practical task capabilities. |
|
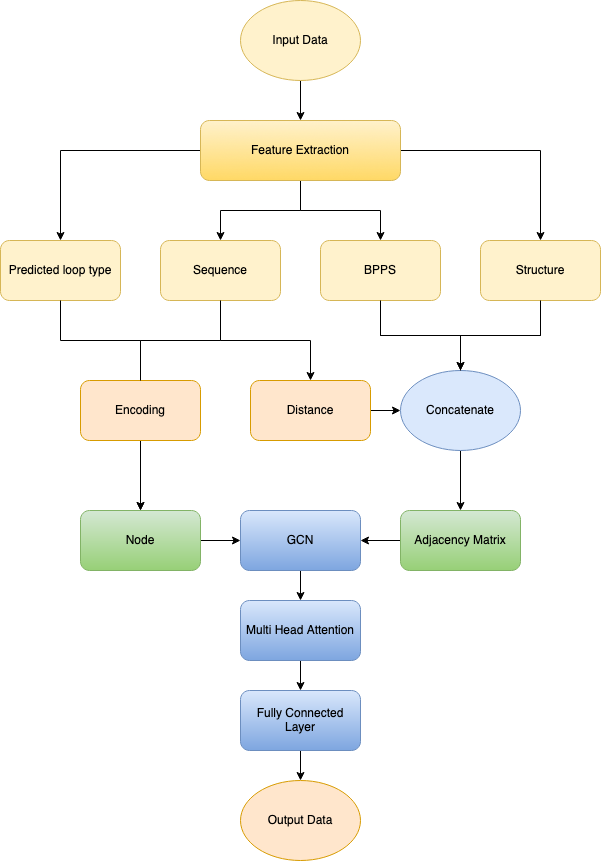
Vyom Pathak*, Rahul Roy* [Code] / [Slides] We compared 2 methods to predict the degradation of the mRNA Vaccine protein structure. We investigate graph-based as well as sequence-to-sequence models for the RNA structure on the Eterna Dataset. Our results show that the graph-based solution better represents the dataset thus giving better performance than the sequence-to-sequence model. |
|
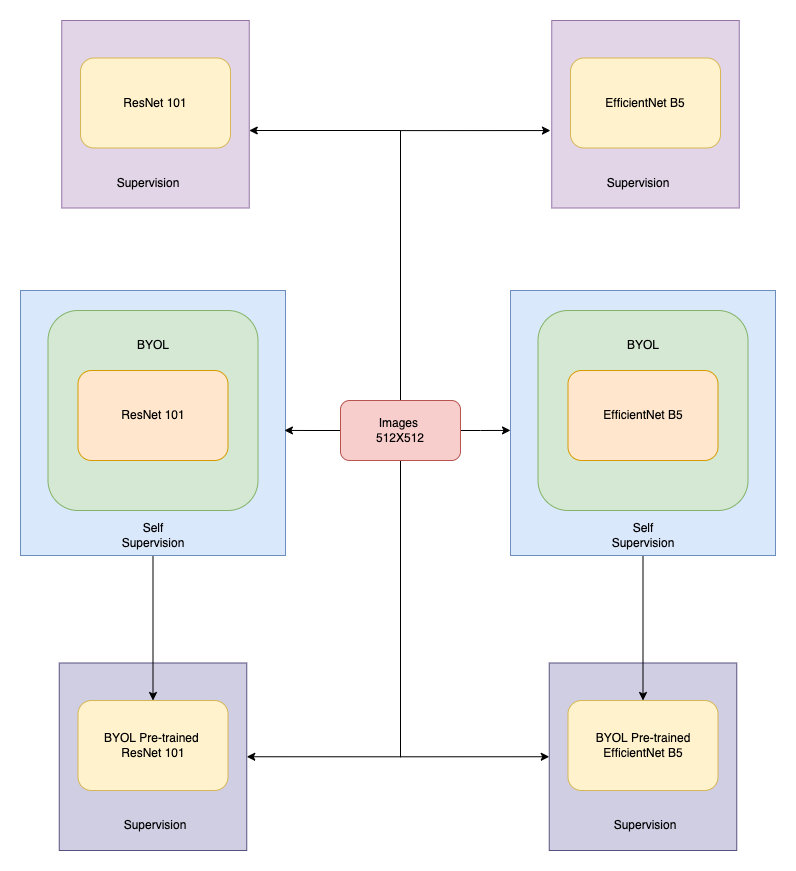
Vyom Pathak*, Sanjana Rao* [Code] / [Slides] We present an ensemble of image-only convolutional neural network (CNN) models with different backbones and input sizes along with a self-supervised model to classify skin lesions. We use the Bootstrap your own latent (BYOL) model for self-supervision on the state-of-the-art image recognition models for performance improvements. With this, we show an improvement of 2% over the baselines. |
|
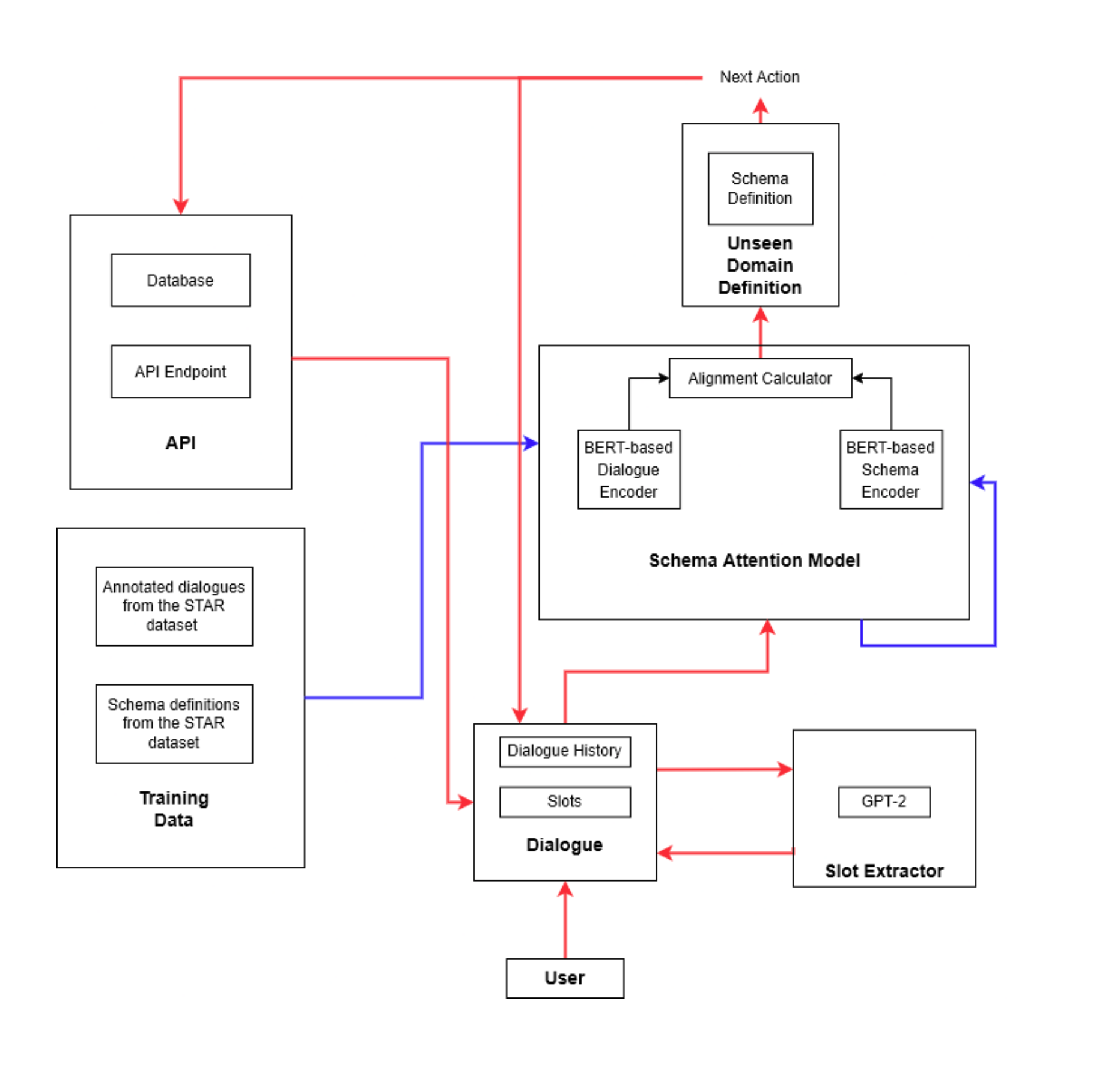
Vyom Pathak*, Amogh Mannekote*, Oluwapemisin Bandy-toyo* [Code] / [Slides] We have developed a Schema-based Dialogue System for Zero-Shot Task Transfer which enables designers to quickly and easily transfer the learned behaviors from related tasks/domains to new domains or tasks. We used zero-shot prompt-based Dialogue-GPT2 for the response generation part. We verified the viability of the system as a wire-framing technique through two user studies. |
|
Vyom Pathak*, Muktan Patel*, Deepang Raval [Post 1] / [Post 2] We participated in a Kaggle competition to predict the difficulty of a comprehensive paragraph as a regression score. We developed a novel 2D-Attention mechanism to boost our performance, along with finetuning several large language models. The final model was an ensemble based on the Forward OOF method which helped us achieve a Silver medal in the competition. |
|
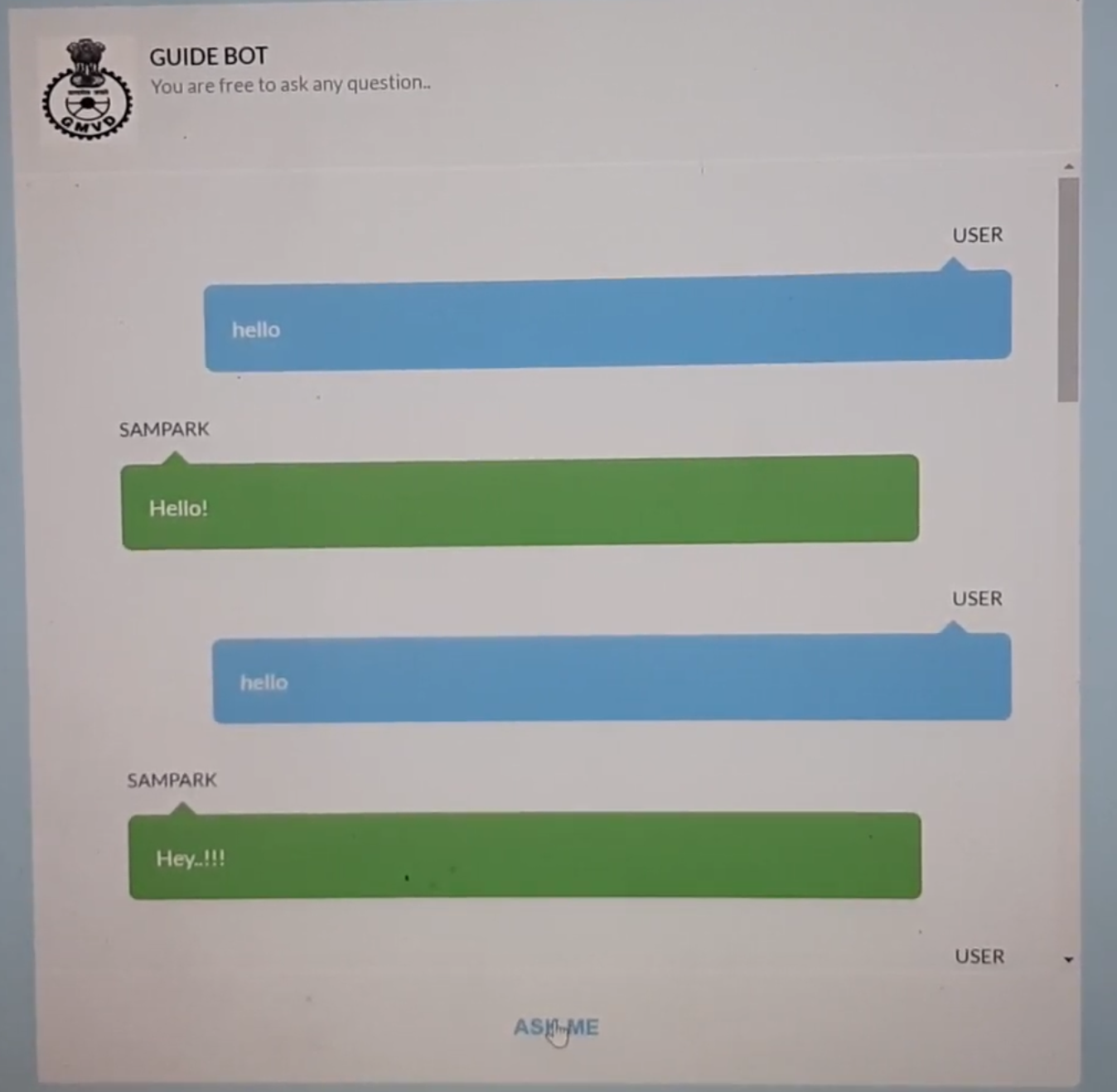
Vyom Pathak*, Muktan Patel*, Deepang Raval*, Utsav Parmar*, Sachin Thakkar* [Video] / [Slides] For the 'Build for Digital India' program, we decided to build a guide-bot for the Regional Transport Office (RTO), Government of India under the theme Smart cities & Infrastructure. A guide-bot that can answer and help people with relevant kinds of queries and confusions usually they have. So the work of people will become easier and correct information can be provided. |
|
|
Vyom Pathak A repository for ML algorithms I implemented ranging from regression models, decision trees, CNN, and NLP concepts; to transfer learning. This repository also houses different papers that I have reviewed along with my thoughts on the same. I update this project with my new learnings. |
|
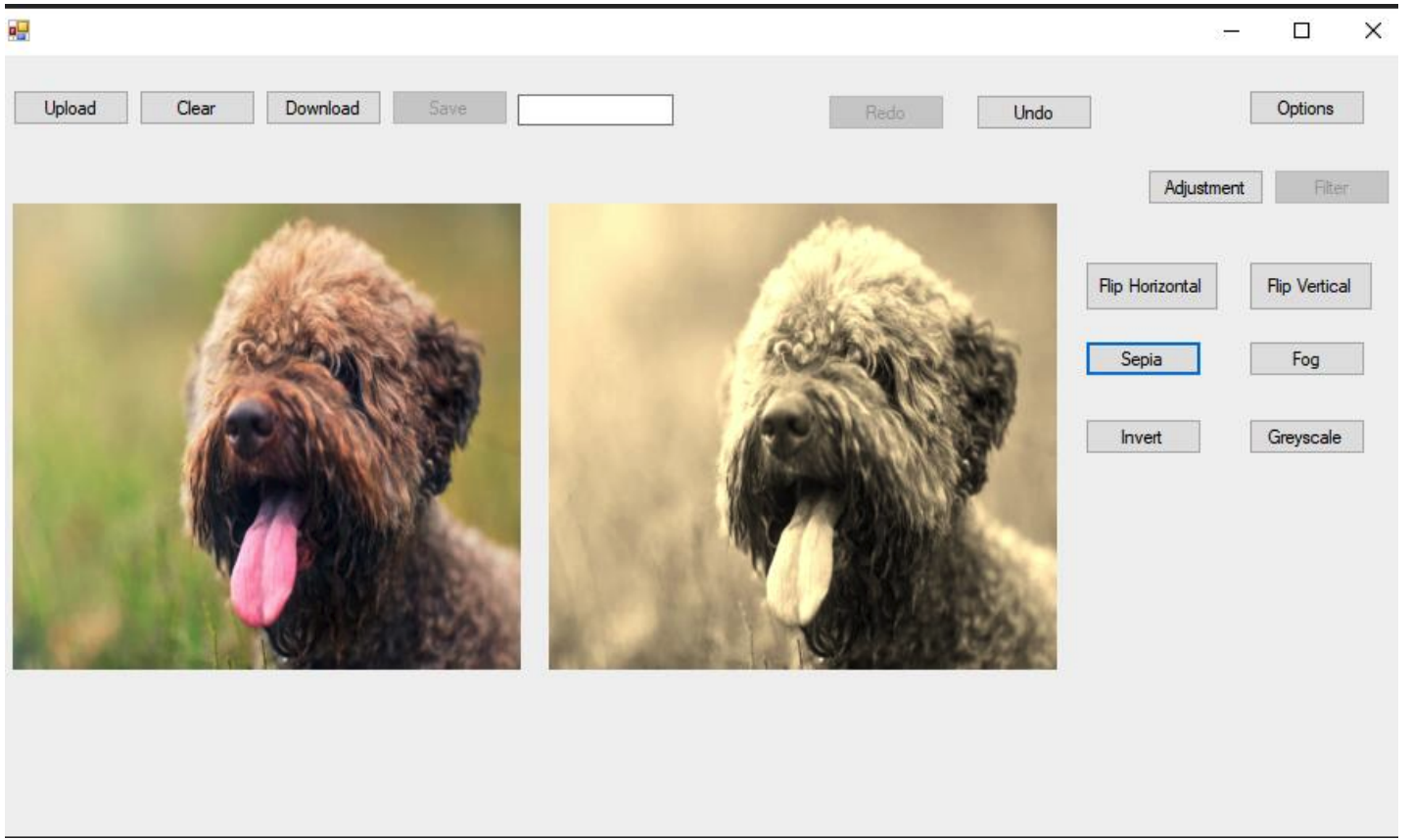
Vyom Pathak [Video] / [Code] This application is used for editing photos. It uses digital image processing based on matrix manipulations for photo editing. needs. The software provides functionalities like image RGB value modification, image styling, image flipping along the axis, image rotation as well as applying some filters on the images like Sepia, Greyscaling, Inverting, etc. |
|
I write about my research and other interesting things including my professional journey, and other helpful guides on the medium. |

|
Vyom Pathak*, Deepang Raval*, Muktan Patel* [Part 1: Understanding Sound] [Part 2: Simple Audio Feature Extraction for Machine Learning] [Part 3: Understanding Different Approaches] We published three blogs about understanding what is Speech Recognition, feature extraction for speech recognition, to approaches to solving the problem using machine learning in the respective blog posts. |

|
Vyom Pathak This is a rough guide on starting one’s journey in machine learning, from foundational statistics to advanced deep learning concepts. |

|
Vyom Pathak My story of landing machine learning internships at Apple and Amazon. A detailed outlook on my professional journey from June 2017 to February 2022. |
|
|
|
Contribution |
I have made contributions in the form of model implementation, bug fixes, document fixes, type fixing, function deprecation, and adding a testing suite. Some of my contributions are in the following open-source projects: PyTorch Ignite, Hugging Face, TensorFlow, Keras, Scikit-learn, Optuna, Pandas, Julia, and Python. You can find more information on my github README. |
|
Honors |
- Program Chair for the 29th International Conference on Neural Information Processing, (ICONIP 2022)
- Silver Medal (Top 3%) in CommonLit Readability Prize Challenge - Secured AIR 446, and Global rank 2124 in Hash Code 2021 - Appointed as the Machine Learning Team Head at DSC by Google, 2020. - Appointed as a Machine Learning Team member at DSC by Google, 2019 - AIR 1987, College 3rd in ACM-ICPC Online coding round 2019 |
|
*These authors contributed equally to this work.
Big thank you to Jon Barron for the website template! Last updated: 28th April 2025 |
